
私はブラウザをVim風に操作できる、ブラウザ拡張Vimmaticを開発しています。 Vimmaticの次期バージョンで、正規表現によるページ内検索をサポートします。 この記事はその機能の実現方法を紹介します。
以前までの実装
正規表現をサポートする前は、単純なテキスト一致によるページ内検索が可能でした。
その中身は window.find() を呼び出していただけです。
非標準APIですが、ほとんどのブラウザで利用可能です。
このメソッドは渡された文字列がページ内に含まれるか調べ、一致する文字列があればその部分を選択します。
Vimmaticで正規表現による検索をサポートするために、 window.find() ではなく独自にページ内検索を実装しました。
Content scriptsとして実装しましたが、基本的にWeb APIのみを使いました。
そのため通所のページにロードされるJavaScriptでも実現可能だと思います。
正規表現によるページ内検索
戦略
ざっくりとした実装の戦略は以下のとおりです。
- HTMLからテキストを抽出
- 抽出したテキストに正規表現でチェック
- マッチする文字列を選択
テキスト選択
正規表現の実装の前にテキスト選択について説明します。 JavaScriptでページ内のテキストを選択するにはSelectionを使います。 選択範囲は始まりと終わりのノードと文字列のオフセットを指定します。
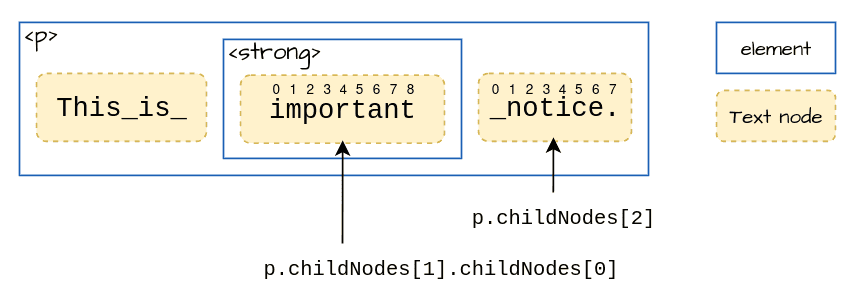
以下のHTMLから “important notice” という文字列を選択する場合を説明します。
<p>This is <strong>important</strong> notice.<p>“important notice” の始まりの位置は <strong> 内のTextノードの1文字目で、終わりは <p> 内の3番目のTextノードの7文字目です。
実装は以下のようになります。
const p = document.querySelector("P");
const range = document.createRange();
range.setStart(p.childNodes[1].childNodes[0], 0);
range.setEnd(p.childNodes[2], 7);
const selection = window.getSelection();
selection.removeAllRanges();
selection.addRange(range);独自にページ内検索を作るには、対象テキストのTextノードとオフセットを知る必要があります。
そのため document.body.innerText をRegExpで検索しても、innerText の文字列内の位置は分かりますが、Textノードを知ることができません。
テキスト抽出
先程解説したとおり document.body.innerText ではTextノードを特定できません。
またHTML内のTextノードを列挙して文字列をテストするだけでは、上記のような複数のTextノードをまたぐ範囲は検索できません。
そこでVimmaticは一連のTextノードを連結した文字列を検索対象とします。
この一連したTextノードをテキストグループと呼ぶことにします。
HTMLはブロックレベル要素とインラインレベル要素があります。
ブロックレベル要素は<p> や <div> などの、垂直方向にレイアウトされる要素です。
インラインレベル要素は<span> や <i> などの、水平方向にレイアウトされる要素です。
Vimmaticは連続するインラインレベル要素に含まれるTextノードをテキストグループとして抽出し、ブロックレベル要素の始まり・終わりはテキストグループの区切りとします。
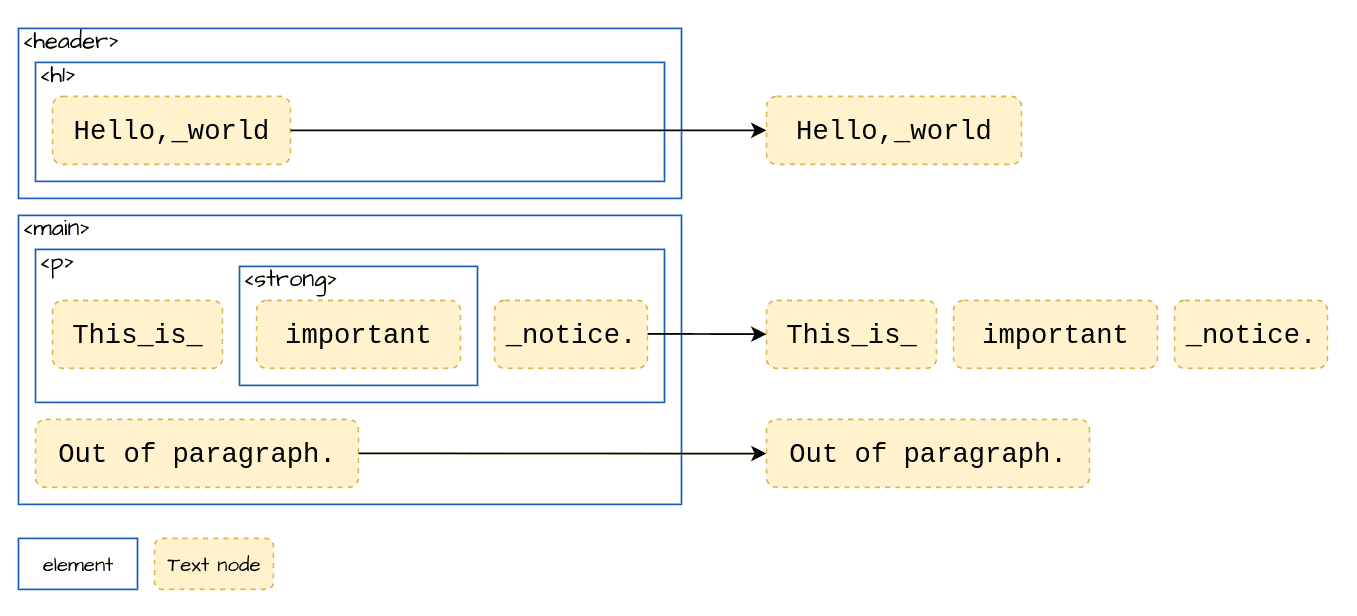
以下のHTMLを例に説明します。
このHTMLには3つのテキストグループが含まれます(正確には <header> と <main> の間や <main> と <p> の間にも改行のTextノードが含まれるがここでは説明を簡単にするために省略)。
<header><h1>Hello, world</h1></header>
<main>
<p>This is <strong>important</strong> notice.<p>
Out of paragraph.
</main>
実装は、<body> から小要素を再帰的に探索して、一連のTextノードを抽出します。
インラインレベル要素の判定はCSSの display プロパティで判断できます。
簡易的実装が以下のとおりです(実際のVimmaticの実装は要素の可視判定等を含みます)。
const getTextGroups = (root: Node): Array<Array<Text>> => {
const textGroups: Array<Array<Text>> = [];
let currentGroup: Array<Text> = [];
const walk = (node: Node) => {
if (!isInline(node) && currentGroup.length > 0) {
textGroups.push(currentGroup);
currentGroup = [];
}
for (const child of Array.from(node.childNodes)) {
if (child instanceof Text) {
currentGroup.push(child);
} else if (child instanceof Element) {
walk(child);
}
}
if (!isInline(node) && currentGroup.length > 0) {
textGroups.push(currentGroup);
currentGroup = [];
}
};
walk(root);
return textGroups;
};RegExpの検索とTextノードのオフセットの取得
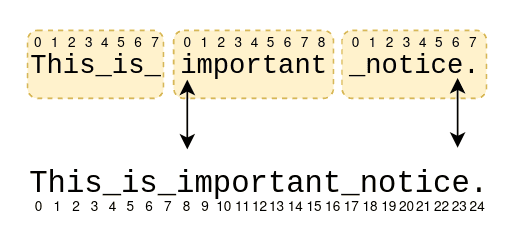
テキストグループのTextノードに含まれる文字列を連結したものはRegExpで検索できます。 RegExpでマッチした結果には、文字列の位置が含まれます。 この文字列の位置からTextノードとオフセットを逆引きすることで、Selectionに渡す情報を取得できます。
type Position = { node: Text; offset: number };
const positionAt = (textGroup: Array<Text>, index: number): Position => {
let current = 0;
for (const node of textGroup) {
const length = node.wholeText.length;
if (current + length > index) {
return { node, offset: index - current };
}
current += length;
}
throw new Error("index out of range");
};