皆さんはシステムを設計する時にスケーラビリティや耐障害性についてどうやって見積もっていますか? The Site Reliability Workbook の第 12 章では、Google 内部で利用されているシステムの設計方法 “Non-Abstract Large System Design”について紹介しています。 この記事ではその設計方法について解説します。
Non-Abstract Large System Design (NALSD) とは
どんなシステムも最終的には、ネットワークに接続されたコンピューター上で実行します。 Google の長年の経験から、SRE は実リソースを見積もる力が必要だと分かりました。 そのためには、Non-Abstract (非抽象的) な設計する能力が必要となります。
NALSD は反復的に設計を繰り返し、各設計の長所・短所を調べます。 それぞれの設計フェーズでは、以下の質問をします。
- 実現可能か : その設計は魔法を使わずに構築できるか?
- もっと良い方法があるか : 合理的に実現できるもっと簡単な方法はないか?
- 実行可能か : 実際の制約条件(予算や時間など)の範囲内に収まるか?
- 回復性はあるか : 障害が発生するとシステムはどうなるか?
ここからは Google AdWords を例にして NALSD の設計プロセスを紹介します。
Google AdWords
Google AdWords は Google 検索にテキスト広告を表示します。 広告主はダッシュボード上で、広告とキーワードごとの CTR (click-through rate) という、広告が表示された回数に対するクリックされた割合を確認できます。
初期要件
広告主が気にするのは、ダッシュボードがすばやく表示され、表示されるデータが最新のものであることです。 各設計フェーズで一貫したゴールを設定するために、ダッシュボードに対して以下の SLO を設定します。
- 99.9%のダッシュボードのクエリが 1 秒未満で完了
- 99.9%の CTR が 5 分以内のデータ
検索クエリと広告クリックは、以下のレートを想定します。
- 500,000 件/秒の検索クエリ
- 10,000 件/秒の広告クリック
単一マシン
CTR の計算は、検索システムと広告配信システムのログから計算できます。 Web 検索時のログをクエリログ 、広告クリック時のログをクリックログと呼びます。 それぞれのログには以下の情報が含まれます。
- クエリログ ... 時刻、クエリ ID、検索キーワード、広告 ID
- クリックログ ... 時刻、クエリ ID、広告 ID
ダッシュボードを表示するのに、毎回クエリログとクリックログをスキャンするのは非効率的です。 クエリ ID と検索キーワードにインデックスを持つデータベースを使用すると、1 秒以内に結果がわかるはずです。 2 つのログをクエリ ID で JOIN すると、それぞれの検索での CTR が分かります。
計算
まずはシステムの容量を見積もるために、ぞれぞれのログの大きさを計算します。
- 時刻 ... 64bit 整数型
- クエリ ID ... 64bit 整数型
- 検索キーワード ... 500 バイト未満の文字列
- 広告 ID ... 3 つの 64bit 整数型
- その他のメタデータ ... 500 - 1,000 バイトの情報
余裕のある見積もりをするために、各クエリログを 2KB に切り上げます。 24 時間で生成されるクエリログは
- (5✕105 クエリ/秒) ✕(8.64 ✕104 秒) ✕(2✕103バイト) = 86.4TB/day
クエリ件数に対して 2%のクリックが発生し、データベース上のインデックスのオーバーヘッドを考慮して、1 日辺り 100TB に切り上げます。 1 日あたり 100TB のディスク書き込みが発生するので、新たな考慮事項が挙げられます。 たとえば一般的な 4TB HDD は 200IOPS です。 各ログに対して 1 回ディスク書き込みするなら、2,500 ディスクが必要となります。
- 5✕105 クエリ/秒 / (200IOPS) = 2,500 ディスク
評価 計算結果を無視したとしても、他の懸念点もあります。 1 台のマシンに収めると、単一障害点が多くなってしまい、マシンの再起動だけでも SLO を下回る可能性があります。
この設計は実現不可能に思えますが、考察することは無駄ではありません。 この情報を元に次の設計を考えます。
LogJoiner
全てのクエリからオンデマンドにクエリ ID で検索できるデータストアを QueryStore と名付けます。 詳しい振る舞いについてはBigtableを参照してください。
CTR ダッシュボードには、広告 ID と検索キーワードに対する、表示回数とクリック回数が必要です。 LogJoiner はクリックログをストリーム処理して、QueryStore のデータに JOIN します。 その結果を広告 ID と検索キーワードをキーにした ClickMap というデータストアに保存します。 また広告 ID と検索キーワードをキーにした、クエリ ID を QueryMap というデータストアに保存します。
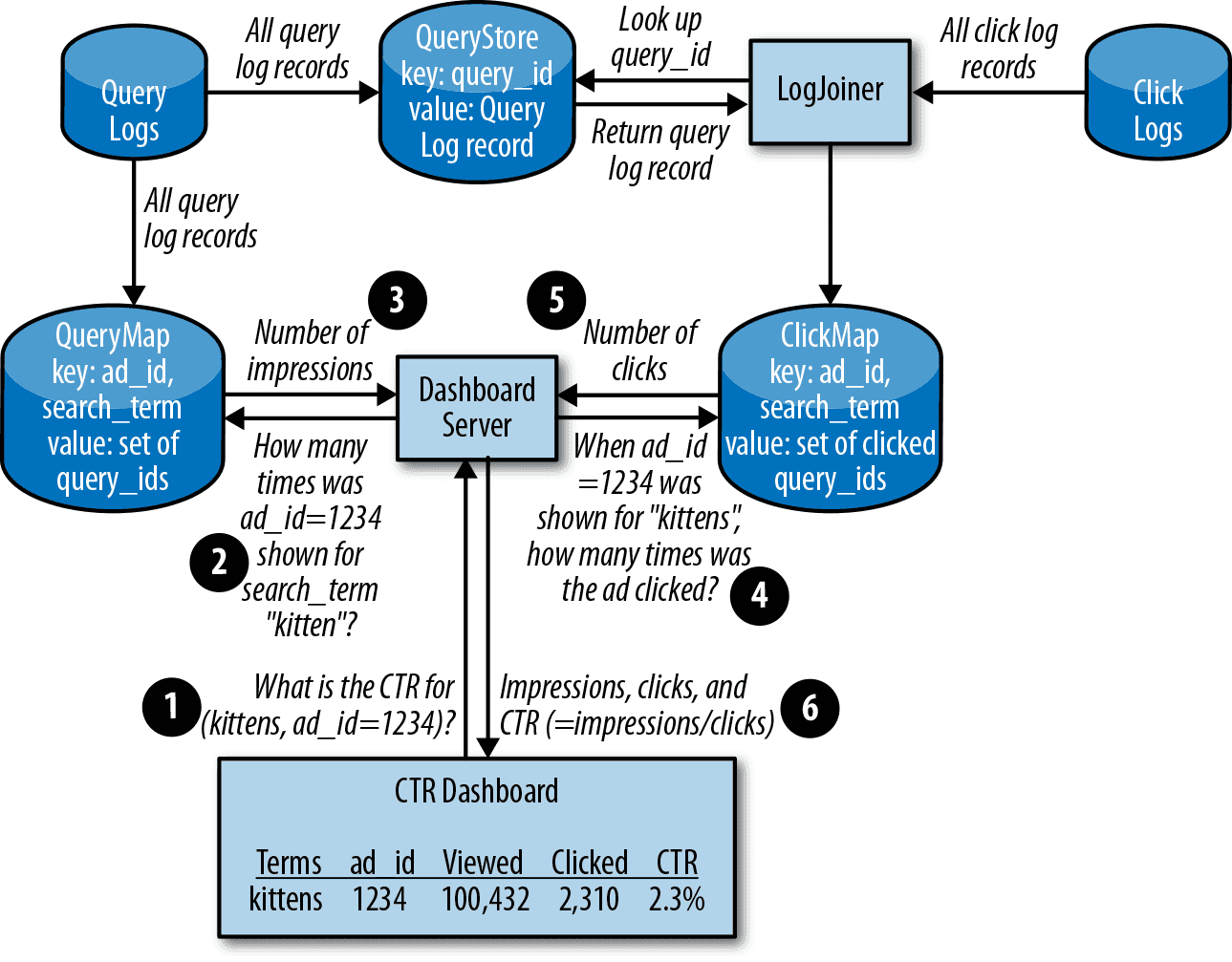
計算
LogJoiner がクリックログを処理するのに必要なネットワークスループットは以下のとおりです。
- (104 クリック/秒) ✕(2 ✕103 bytes) = 160 Mbps
LogJoiner はクエリ ID から該当のクエリログを JOIN するために、QueryStore にアクセスします。 その時に必要なネットワークスループットは以下のとおりです。
- (104 クリック/秒) ✕(8 bytes) = 640 Kbps
- (104 クリック/秒) ✕(2 ✕103 bytes) = 160 Mbps
LogJoiner は JOIN した結果から、クエリ ID、広告 ID、検索キーワード、時刻を ClickMap に保存します。 これらのデータは 1KB 未満であるため、保存に必要なネットワークスループットは以下のとおりです。
- (104 クリック/秒) ✕(103 bytes) = 80 Mbps
合計で 400Mbps なので、実現可能な転送速度です。
続いてデータサイズです。 ClickMap はクリック毎の時刻とクエリ ID が保存されます。 広告 ID と検索キーワードは線形係数が小さいので無視します。 ClickMap の 1 日あたりのデータサイズは次のとおりです。
- (104 クリック/秒) ✕(8.64 ✕104 秒) ✕(8 bytes + 8 bytes) = 14 GB/day
オーバーヘッドを考慮して 1 日 20GB に切り上げます。
QueryMap はクエリ ID ごとの広告 ID を保存します。 各検索には 3 つの広告 ID が表示されるので、1 日あたりの QueryMap のデータサイズは以下のとおりです。
- 3 ✕ (5 ✕105 クエリ/秒) ✕(8.64 ✕104 秒) ✕(8 bytes + 8 bytes) = 2 TB/day
2TB は十分小さいですが、単一マシンの設計よりハードドライブに保存できない事がわかっています。 次のステップでは LogJoiner のシャーディングを考えます。
LogJoiner のシャーディング
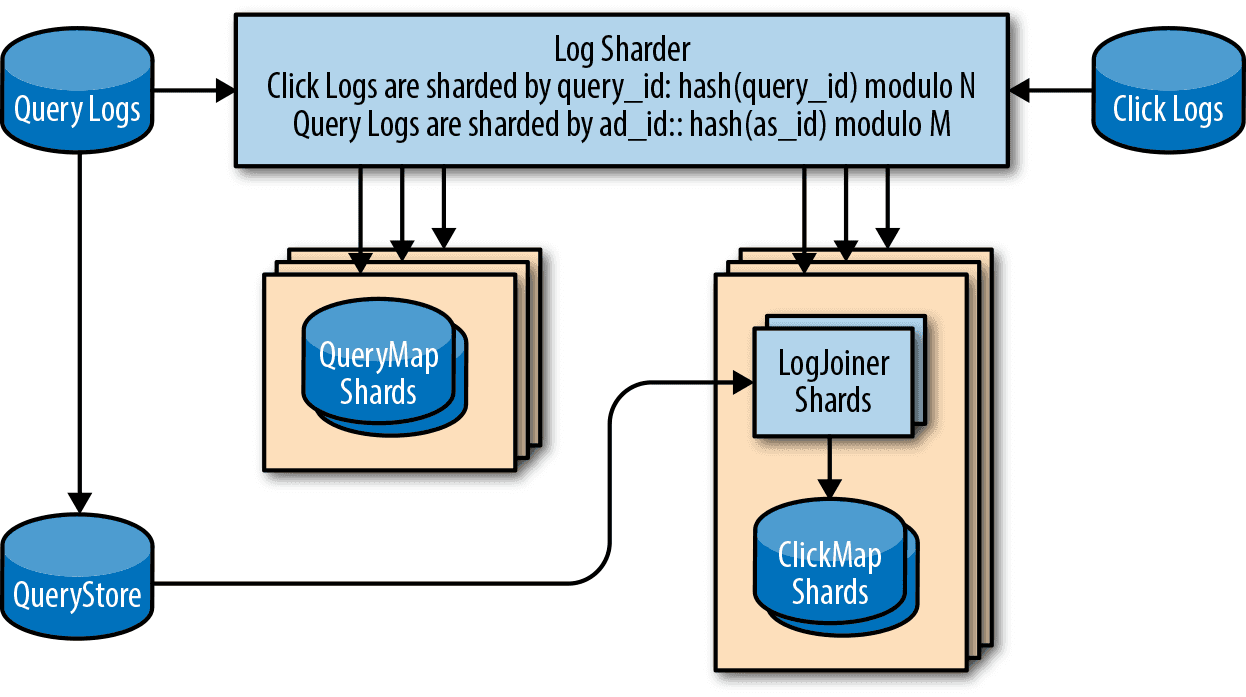
クエリログとクリックログを JOIN できることがわかりました。 クエリ ID のハッシュ値をシャード数 N で mod して送信先の LogJoiner を選ぶと、複数の LogJoiner を並列に実行できます。 クリック数が増えても、LogJoiner を水平スケールすることで対応できます。
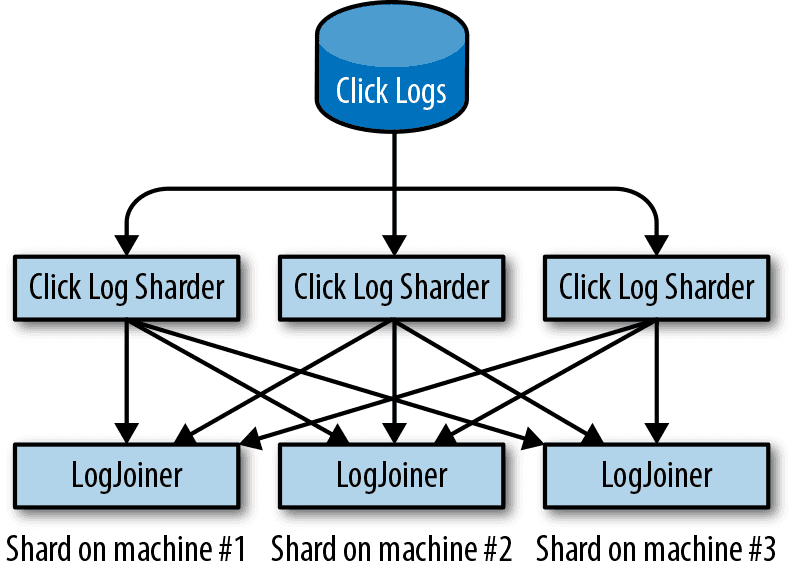
QueryMap が必要な IOPS を維持するには、同様にシャーディングが必要です。 QueryMap は広告 ID でシャーディングします。
システムにスケーラビリティがあるのは分かりました。 次の問題は信頼性です。 今の設計では LogJoiner の結果を保存する前にクラッシュすると、その作業をやり直す必要があります。 そのためダッシュボードへの反映が遅れて SLO に影響します。 LogSharder が 2 つのシャードに同じログを送ることで、1 つの LogJoiner に障害が発生しても問題ありません。
シャードの複製を作成することで、障害による影響を減らせますが、ゼロにはできません。 それはエラーバジェットがリスクをカバーします。
評価 シャーディングされたコンポーネントで処理できるのが分かりました。 しかし 1 つのデータセンターでホストすると単一障害点となります。 複数データセンターを使用するよう設計を進化する必要があります。
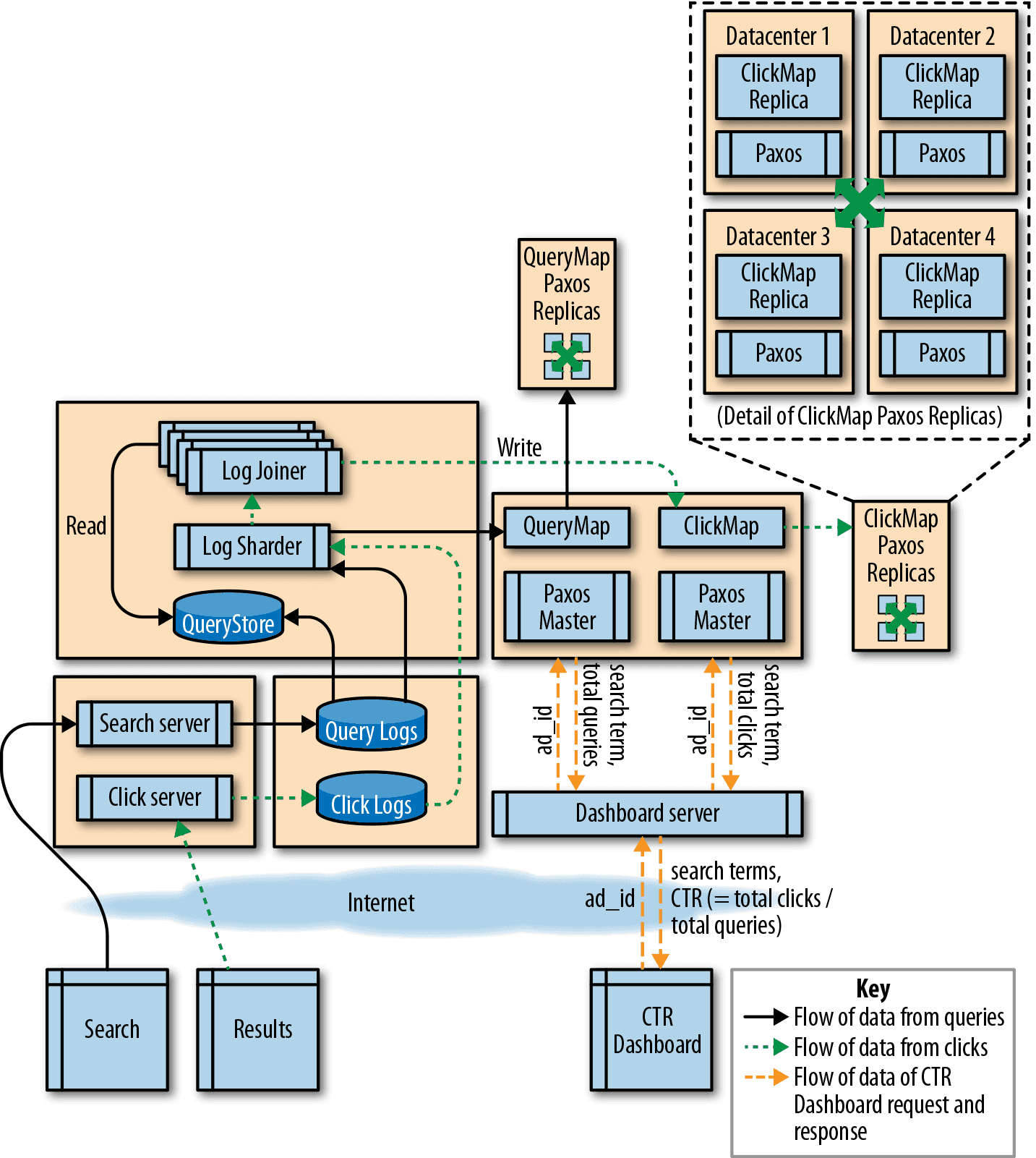
複数データセンター
複数データセンターで実行可能な ClickMap は実現可能でしょうか? 一般的な分散システムを構築するときは、3 または 5 のレプリカを作成して、Paxosのような合意アルゴリズムを使用します。 果たしてこれは実際に機能するでしょうか。 またどんなリソースがどれくらい必要になるでしょうか。
計算 数百 km 離れた DC 間で Paxos アルゴリズムを実行するにはおよそ 25 ミリ秒かかるのがわかっています。 つまり毎秒 40 回までのオペレーションしか実行できません。 LogJoiner のシャーディングの設計で各ログにレプリカを導入するので、1 秒あたりのトランサクション数を 2 倍にし、20,000 クリック/秒と 1,000,000 クエリ/秒で計算します。
1 秒あたりのクエリ数をオペレーション数で割ることで、必要なタスクの最少数が分かります。
- (1.02 ✕106 クエリ/秒) / (40 オペレーション/秒) = 25,500 タスク
各タスクのメモリ量 (2TB の QueryMap) は
- (4 ✕1012 bytes) / (25,500 tasks) = 157 MB/task
そしてマシン毎のタスク数は
- (6.4 ✕1010 bytes) / (1.57 ✕108 bytes) = 408 タスク/マシン
1 台に多くのタスクを集約できることが分かります。
ClickMap と QueryStore の合計スループットは
- (1.02 ✕106 クエリ/秒) ✕(2 ✕103 bytes) = 16 Gbps
タスク毎のスループットは
- 16 Gbps / 25,500 tasks = 80 KB/秒 = 640 Kbps/タスク
そしてマシン毎のスループットは
- 408 tasks ✕640 Kbps/task = 256 Mbps
各マシンに 64GB RAM がある場合 64 台のマシンでデータを提供でき、ネットワークインターフェイスが 1Gbps なら 25%の帯域しか使用しません。
おわりに
この記事では Google で利用されている、システムの設計方法を解説しました。 設計プロセスは単一のマシンから始まり、複数 DC で稼働する、スケーラビリティや耐障害性を備えたシステムができあがりました。 それぞれの設計フェーズで元の要件を満たすだけでなく、耐障害性などの新たな要件も発見できました。
本文中に、突然 Bigtable が出てきたり、QueryStore への転送について原文でも解説されていませんでしたが、おそらく紹介した NALSD を使って同様に設計することができます。
実際はスケールできるマネージドサービスを使ったり、複数 DC で稼働するシステムを直接実装することは多くないとは思います。 しかしそれらを組み合わせても、スケーラビリティや耐障害性と SLO への影響は常に考えておく必要があります。 たとえパブリッククラウドを利用していたとしても、この章で紹介されている設計方法は役立つでしょう。