
SRE やサービスを運用している皆さんは、アラートの閾値をどのように決めていますか? The Site Reliability Workbook のChapter 5 - Alerting on SLOsには、アラートに関する興味深い記述があるので、改めてこの記事で説明してみようと思います。
SLO とアラート
Web サービスやシステムは、予期せぬパフォーマンス劣化やエラーが発生する事があります。 このとき緊急対応できるように、管理者はアラートを設定します。 このアラートの基準に SLO(Service Level Objective: サービスレベル目標) を用いるのがプラクティスの 1 つです。
SLO に基づくアラートは、ユーザーに影響がある障害や、SLO を守ることができない重大障害に気づけます。 アラートの閾値に SLO の基準値を利用するのが、明快で理解しやすいアラートの設定方法の 1 つです。 SLO に「月間リクエストの成功率が 99.9%」を設定しているのならば、10 分ウィンドウでエラーレートが 0.1%を超えたらアラートを鳴らす、などです。 しかし一方で、アラートが機敏すぎるという問題もあります。 ロールアウトに伴う一時的なエラーや、SLO を達成できるほどエラーバジェットが十分残っている場合でもアラートが鳴る可能性もあります。
アラートはサービスの健康状態を守るために必要ですが、対応チームの健康状態にも気をつける必要があります。 The Site Reliability Workbook のChapter 5 - Alerting on SLOsには、エラーバジェットを消費する速度に注目した バーンレート を使って、適切なアラートを設定する方法が説明されています。 この記事では SLO の基準値を使ったアラートの問題点と、バーンレートに基づくアラートを紹介します。
SLO の基準値に基づくアラート
まずは広く用いられている、固定の時間内で SLO の基準値を元にしたアラートです。 基準値がわかりやすく計算も簡単なので、この方針を採用している人は多いのでは無いでしょうか?
たとえば SLO に「月間のリクエスト成功率が 99.9%」を設定しているとします。 まずは 10 分ウィンドウでエラーレート 0.1%を超えた場合にアラートを鳴らしてみましょう。
- alert: HighErrorRate
expr: job:slo_errors_per_request:ratio_rate10m{job="myjob"} >= 0.001このアラートは、エラーが発生してから即座に検出できますが、一方で過敏すぎるというデメリットがあります。 たとえば 10 分ウィンドウで 0.1%のエラーレートが発生した場合、1 ヶ月のエラーバジェットの 0.02%しか消費しません。 極端な例で例えると、1 日に最大 144 回のアクションがいらないアラートを毎日受け取っても、SLO を満たせる可能性があるのです。
ウィンドウ幅の拡大
さきほどのアラート基準は過敏だというのがわかりました。 今度は 10 分ではなく、36 時間ウィンドウで集計します。
- alert: HighErrorRate
expr: job:slo_errors_per_request:ratio_rate36h{job="myjob"} > 0.001
この基準値では、全断(エラーレート 100%)した場合でも、2 分 10 秒で検知でき、相変わらず優れた検出時間です。 しかし一方で、ウィンドウが長くなると、アラートがリセットされるまでの時間も長くなります。 例えばエラーレート 100%で一度閾値を上回ると、次の 36 時間後まで正常な値に戻りません。 その間に再びエラーレートが上がったとしても、新たな障害に気付くことができません。
バーンレートに基づくアラート
バーンレート はエラーバジェットの消費速度を表す指標です。 バーンレートに基づくアラートは、エラーバジェットが枯渇する勢いのエラーが発生したときにのみアラートを鳴らすことができます。 SLO を達成できないリスクがある時に緊急対応をして、それ以外の一時的なエラーやエラーバジェットが十分残っているならアラートは鳴りません。
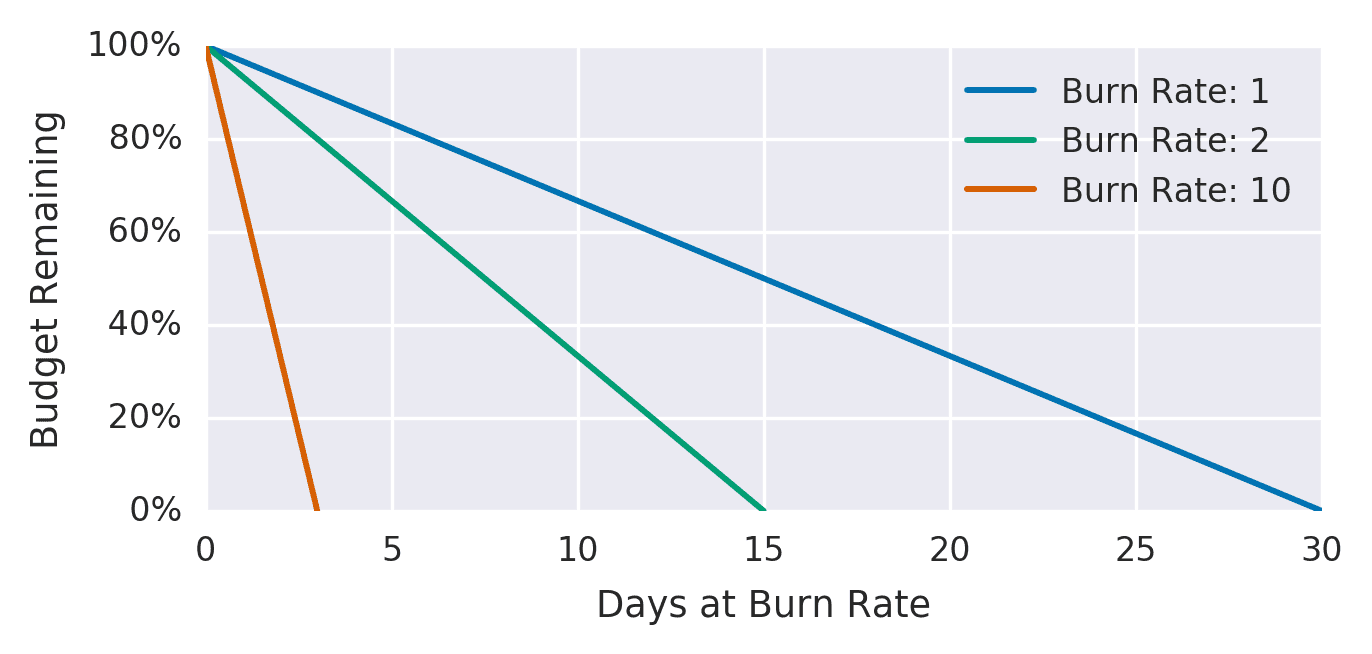
以下の図はバーンレートとエラーバジェットの消費量の関係です(The Site Reliability Workbook Figure 5-4)。 SLO の期間内でちょうどエラーバジェットを使い切る消費速度を、バーンレート 1 とします。 バーンレート 1 はちょうど 1 ヶ月後にエラーバジェットが 0 になります。 バーンレート 2 はその 2 倍の速度でエラーバジェットを消費し、15 日後にエラーバジェットが 0 になります。
バーンレートベースのアラートにおける、検出時間は以下の式で表せます。
- ((1 - SLO) / エラーレート) _ ウィンドウサイズ _ バーンレート
また検出までの時間に消費するエラーバジェットの割合は以下のとおりです。
- (バーンレート * ウィンドウサイズ) / SLO の期間
例えば SLO が「月間リクエストの成功率が 99.9%」で、ウィンドウサイズ 1 時間でエラーバジェットのうち 5%を消費した場合に知りたいとします。 1 時間でエラーバジェットの 5%を消費する速度はバーンレート 36 です。
- alert: HighErrorRate
expr: job:slo_errors_per_request:ratio_rate1h{job="myjob"} > 36 * 0.001複数バーンレートの組み合わせ
The Site Reliability Workbook には、まずは 1 時間でエラーバジェットの 2%を消費、または 6 時間でエラーバジェットの 5%を消費するときに緊急対応をして、3 日間で 10%のエラーバジェットを消費した時にチケットで対応するところから始めるのが良いとあります。
| エラーバジェット消費量 | ウィンドウ幅 | バーンレート | 通知方法 |
|---|---|---|---|
| 2% | 1 時間 | 14.4 | 緊急対応 |
| 5% | 6 時間 | 6 | 緊急対応 |
| 10% | 3 日 | 1 | チケット |
expr: (
job:slo_errors_per_request:ratio_rate1h{job="myjob"} > (14.4*0.001)
or
job:slo_errors_per_request:ratio_rate6h{job="myjob"} > (6*0.001)
)
severity: page
expr: job:slo_errors_per_request:ratio_rate3d{job="myjob"} > 0.001
severity: ticketここでもまた、アラートがリセットされる時間は長いです。 例えばエラーレート 100%で閾値を上回ると、次の 6 時間後まで正常な値に戻りません。 SLO 99.9%に設定しているのなら、エラーレートが再上昇しても気付かずに、エラーバジェットを使い切ってしまいます。 そこで次に示す、短いウィンドウとの組み合わせる方法があります。
短いウィンドウとバーンレートの組み合わせ
先程のアラートはリセットまでの時間が長いという問題がありました。 そこでウィンドウ幅が 1 時間/6 時間/3 日それぞれに対して、さらに短いウィンドウを組み合わせるというテクニックがあります。 The Site Reliability Workbook には、短いウィンドウに 1/12 の長さを使うと良いとあります。
expr: (
job:slo_errors_per_request:ratio_rate1h{job="myjob"} > (14.4*0.001)
and
job:slo_errors_per_request:ratio_rate5m{job="myjob"} > (14.4*0.001)
)
or
(
job:slo_errors_per_request:ratio_rate6h{job="myjob"} > (6*0.001)
and
job:slo_errors_per_request:ratio_rate30m{job="myjob"} > (6*0.001)
)
severity: page
expr: (
job:slo_errors_per_request:ratio_rate24h{job="myjob"} > (3*0.001)
and
job:slo_errors_per_request:ratio_rate2h{job="myjob"} > (3*0.001)
)
or
(
job:slo_errors_per_request:ratio_rate3d{job="myjob"} > 0.001
and
job:slo_errors_per_request:ratio_rate6h{job="myjob"} > 0.001
)
severity: ticketたとえばエラーレート 100%になると、長いウィンドウと短いウィンドウの両方で閾値を上回ります。 エラーレートが下がってからしばらく経つと、短いウィンドウのエラーレートが閾値を下回り、アラートも正常値に戻ります。 再びエラーレートが上がった場合には、またアラートが異常値を知らせて問題の再発を検知できます。 このアラートは長い期間待たずとも一度アラートが正常値に戻るので、知らず知らずのうちにエラーバジェットが枯渇するのを防ぎます。
おわりに
エラーバジェットに基づくアラートは理にかなっている一方で、少し計算が難しく自分も理解に時間がかかりました。 Google が推奨している 1 時間/6 時間もスタート地点であり、ここからサービスやリクエストの特性に応じてチューニングすることになると思います。 現在アラート地獄に悩まされている方や、それによってアドホックにアラートを緩和している人は、エラーバジェットに基づくアラートを検討してみてはいかがでしょうか?