この記事は Distributed computing Advent Calendar 2017 20 日目の記事です。

Kafka のレプリケーションは、高可用性と高信頼性を実現するための、重要な機能の 1 つです。 この記事では、Kafka のレプリケーションの仕組みについて紹介します。
レプリケーションの基礎
Kafka のデータストリームの最小単位はパーティションです。またレプリケーションもパーティション単位で行われます。
Kafka のレプリケーションの情報は、ZooKeeper 上に保存されています。
レプリカの配置情報は、${prefix}/brokers/topics/${topic} に JSON で保存されます。
{ "version": 1, "partitions": { "0": [0, 1], "1": [1, 2] } }トピック作成時にはレプリカ数を指定します。
たとえば、Kafka 付属の kafka-topics.sh では --replication-factor で指定します。
bin/kafka-topics.sh \
--zookeeper my-zookeeper:2181/${prefix} --create \
--topic my-topic --partitions 2 \
--replication-factor 3またトピックを自動作成するときは、ブローカーの設定で default.replication.factor を指定します。
Kafka のレプリカは、どれか 1 つがリーダーとなり、Producer・Consumer からの読み書きを処理します。
クライアントがリーダー以外のパーティションに対して読み書きを行おうとすると。ブローカーはNotLeaderForPartition を返します。
リーダー以外のレプリカはフォロワーと呼びます。
フォロワーはリーダーらメッセージを取得して、レプリケーションします。
リーダーはクライアントからのリクエスト処理以外にも、フォロワーのレプリケーション状況の管理などもします。
フォロワーがリーダーに追いついているレプリカを、in-sync レプリカ (in-sync replica : ISR) と呼びます。 またリーダーも in-sync replica です。 ネットワークの瞬断などで、レプリケーションに遅延が発生することがあります。 フォロワーのレプリケーションがある一定以上送れると、in-sync replica ではなくなることもあります。
メッセージが Kafka に保存されるまで
Producer が Kafka に書き込んだデータは、Consumer はすぐに読み込めるというわけではありません。 もしそれが可能なら、Consumer 間で処理するデータの一貫性が失われるからです。
Kafka のキューにはhigh water markという概念があります。 high water mark は「ここまではデータが保証されている」という印で、Consumer は high water mark までのデータのみ取得できます。 Producer 書き込み時に、全ての in-sync replica がメッセージを受け取ると、high water mark が進みます。 そのとき全ての in-sync replica が書き込めたメッセージはコミットされた、とよびます(オフセットのコミットとは異なるので注意)。
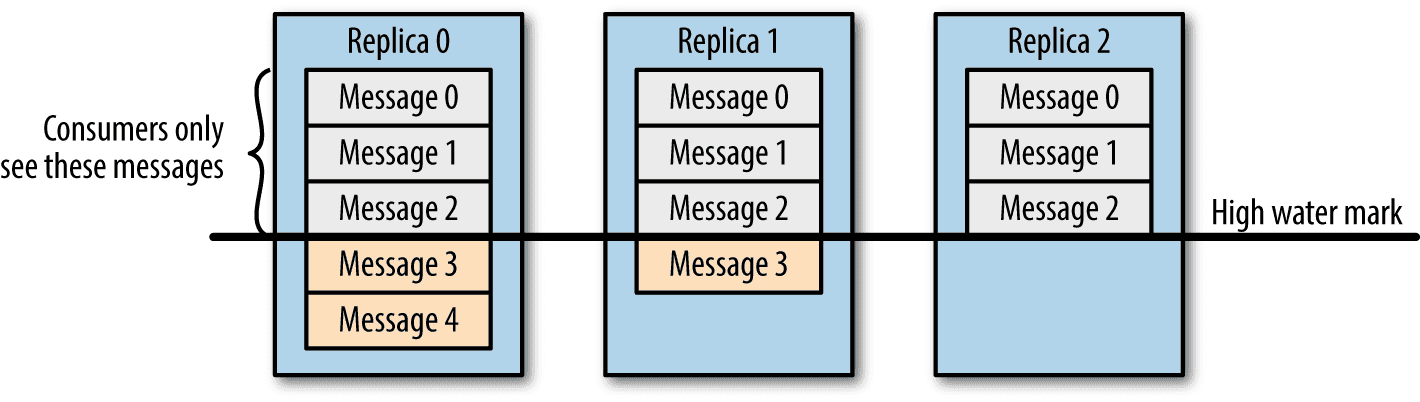
Consumerはin-sync replicaに保存されたデータのみ取得できる (Kafka: The Definitive Guideより)
もし high water mark という概念がないとどうなるでしょうか。 ある Consumer Cが図中の replica 0 の Message 4 を取得できたとします。 その後 Replica 0 を持つブローカーがクラッシュしてデータが失われたとします。 すると Message 4 が永久に失われ、結果としてCと他の Consumer で取得できるメッセージで不整合が生じます。 Kafka は high water mark までのメッセージを読み込めるようにすることで、Consumer 間の一貫性を保ちます。
acks
Producer は信頼性向上のために、メッセージを保存する時に in-sync replica に保存されるまで待つことができます。
acks=all が設定されていると、Producer は全ての in-sync replica にメッセージが書かれるまで待ちます。
acks=1 は、リーダーのみに書き込まれた時点で、Producer に ack を返します。
リーダーのみがメッセージを持っている状態でクラッシュすると、データを失う可能性があります。
acks=0 は、Producer のソケットバッファに追加されると、Producer は送信したとみなします。
これは非常にスループットは高いですが、信頼性は低いので使うことをおすすめしません。
たとえば送り先がリーダーじゃない場合でも、Producer はネットワークに書き込みをした時点で送信できたことになるので、データを失う可能性が非常に高いです。
ここで、あるレプリカの全てのフォロワーが、ネットワーク遅延で in-sync replica から外れた状況を考えます。
なので in-sync replica はリーダーのみです。
こんとき Producer が acks=all を設定してると、全ての in-sync replica はリーダーのみで、リーダーがメッセージを受け取ると書き込みが成功します。
これは正しい動作ですが、そのメッセージを持つのはリーダーのみなので、信頼性を保証できません。
これを防ぐために、ブローカーに min.insync.replicas を設定します。
ブローカーの設定 min.insync.replicas は、書き込みする in-sync replica の最小数を指定できます。
たとえば min.insync.replicas=2 に設定すると、in-sync replica が最低限 2 つ存在することを要求するので、in-sync replica がリーダーのみの場合メッセージを書き込めません。
このときブローカーは Producer に NotEnoughReplicas を返します。
ブローカー故障時の復帰処理
Kafka は他の分散システムのように、ブローカー故障時に別のノードに最レプリケーションは行いません。 ブローカーがクラスタから抜けても、レプリカの配置情報は ZooKeeper に残り続けます。 なのでノードが復帰した時、続きをリーダーから取得すれば良いので、高速にクラスタを復帰できます。 リーダーが故障すると、残った別の in-sync replica から、新たなリーダーが再選出されます。
上記の in-sync replica からのリーダー選出は、"clean"なリーダー選出と呼ばれ、データロスやデータの不整合は発生しません。
他の in-sync replica が存在しないときにリーダーが故障すると、次のリーダーが選出されないのでパーティションは停止します。
このとき in-sync replica だったレプリカが復活するまで、パーティションは停止したままです。
可用性を優先する場合、in-sync ではないレプリカからのリーダー再選出を許すことができます(これを"unclean"なリーダー選出と呼ぶ)。
ブローカーに unclean.leader.election.enable=true を設定するとで有効にできます。
ただし"unclean"なリーダー選出を有効にすると、データロスや Consumer ごとのデータ不整合などが発生する可能性があります。
なので可用性を優先しない限り有効化するべきでは無いです。
まとめ
以上の設定は、Kafka の信頼性や可用性を担保するために必要なパラメータです。 システムの目的により、 これらのパラメータの値を調整する必要があります。 また信頼性や可用性は、 リソースのキャパシティやスループットとトレードオフの関係にあります。 たとえばレプリカ数を増やすと、耐故障性は向上しますが、必要なディスク容量も増えます。
Kafka Document のA Production Server Config には、
例として min.insync.replicas=2 default.replication.factor=3 が設定されてます。
これで、可用性については 1 ノードの故障まで耐えれます。データ損失に対しては 2 ノードまでの故障に耐えれます。
もちろんこれは Producer が acks=all を設定している前提です。
Kafka ではメッセージがコミットされるタイミングは、ディスクに書かれたタイミングではないです。
なのでシビアなタイミングでクラッシュするとデータが消える恐れがあります。
flush.ms, flush.messages を設定して fsync の間隔を設定することで、さらに信頼性の高いシステムも構築できます。